Details of how to construct the database, how to write the report form and how to generate reports using the form are described below.
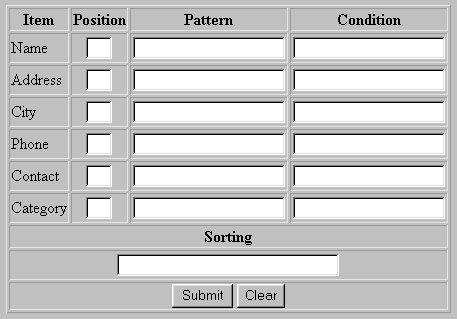
The database consists of records containing Name, Address, City, Phone, Contact and Category fields. The report form is arranged in a table and contains a row for each field in the corresponding database. Each row is named with the name of the corresponding field. Each row contains three text inputs which are named positionn, patternn, and conditionn where n is the row number. These rows are followed by a sorting input and the two control buttons which are the same for all databases. These are followed by two required hidden inputs and an optional hidden input. The first hidden input specifies a list of headers separated by commas. These headers are used in the generated reports. The second hidden input specifies the full path of the database. The optional hidden input specifies case insensitive pattern matching and/or record numbering and for both options would be entered as:
<INPUT TYPE=hidden NAME=options VALUE="case insensitive, record numbers">
The Oregon Cities database
here has such an entry.
To write a report form for a new database do the following:
The form controls:
| Expression | Description |
|---|---|
| . | Matches any character except newline |
| [a-z0-9] | Matches any single character of set |
| [^a-z0-9] | Matches any single character not in set |
| \d | Matches a digit, same as [0-9] |
| \D | Matches a non-digit, same as [^0-9] |
| \w | Matches an alphanumeric (word) character [a-zA-Z0-9_] |
| \W | Matches a non-word character [^a-zA-Z0-9_] |
| \s | Matches a whitespace character (space, tab, newline...) |
| \S | Matches a non-whitespace character |
| \n | Matches a newline |
| \r | Matches a return |
| \t | Matches a tab |
| \f | Matches a formfeed |
| \b | Matches a backspace (inside [] only) |
| \0 | Matches a null character |
| \000 | Also matches a null character because... |
| \nnn | Matches an ASCII character of that octal value |
| \Xnn | Matches an ASCII character of that hexadecimal value |
| \cX | Matches an ASCII control character |
| \metachar | Matches the character itself (\|,\.,\*...) |
| (abc) | Remembers the match for later backreferences |
| \1 | Matches whatever first of parenthesis matched |
| \2 | Matches whatever second of parenthesis matched |
| \3 | and so on... |
| x? | Matches 0 or 1 x's, where x is any of the above |
| x* | Matches 0 or more x's |
| x+ | Matches 1 or more x's |
| x{m,n} | Matches at least m x's but no more than n |
| abc | Matches all of a, b and c in order |
| fee|fie|foe | Matches one of fee, fie or foe |
| \b | Matches a word boundary (outside [] only) |
| \B | Matches a non-word boundary |
| ^ | Anchors match to the beginning of field |
| $ | Anchors match to the end of a field |
This script was written by Brian Prentice. It is currently considered to be a prototype. Any suggestions for how it might be improved to be more useful should be sent to bprentice@webenet.net.